

【やってみた】 "Gemini 1.5 Pro"の活用事例6選

はじめに
Googleが開発した大規模言語モデルのGemini 1.5 Pro。
長文の処理能力や、画像・音声の理解など、マルチモーダルな対応力を持ち、様々なタスクに応用できることが特徴です。
本記事では、Gemini 1.5 Proの活用事例を具体的に紹介し、その可能性を探っていきます!
画像解析
【Gemini 1.5 Proの性能が群を抜いてすごい件。GPT-4、Claude 3を凌駕】
— チャエン | 重要AIニュースを毎日発信⚡️ (@masahirochaen) April 4, 2024
目でも見えないくらい細かい生成AI企業のカオスマップをGemini 1.5 Pronで解析したところ、5分くらいずっとAIが動いて企業名を書き出した。
GPT-4:解析不能
Claude 3:本当に一部のみ
比較すると差は歴然。… pic.twitter.com/CPNZBApPcT
この画像に含まれる全ての企業名を正確にリストアップしてください。
プロンプトと一緒に以下の画像を挿入
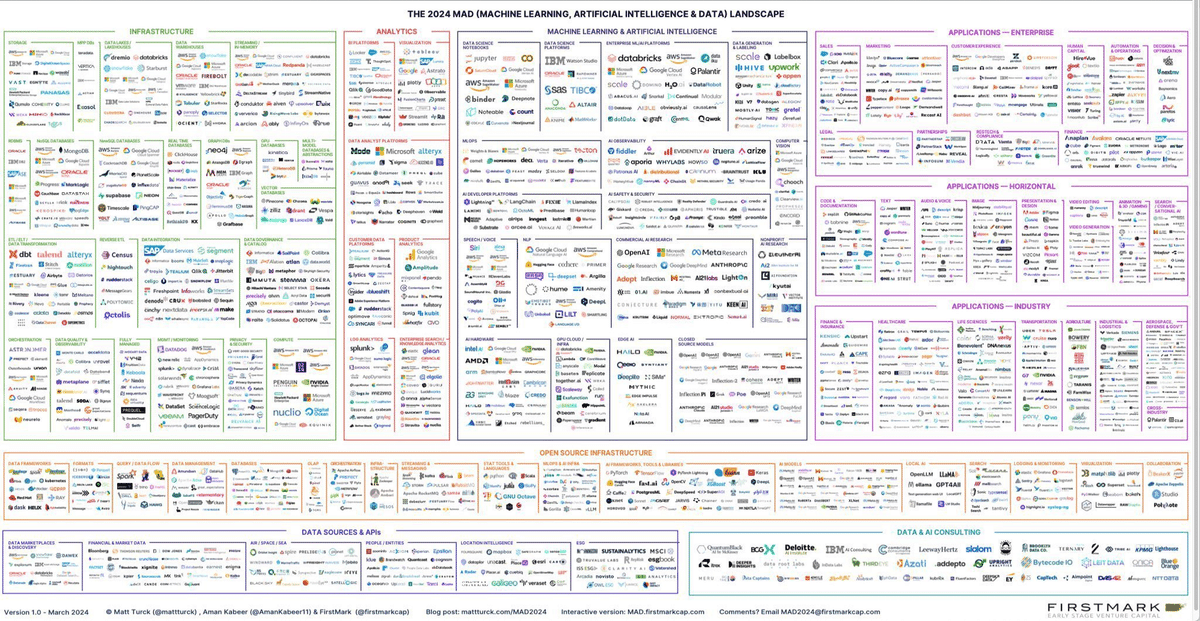

出力全文:
Gemini 1.5 Proの画像解析能力は非常に優れています。
複雑で詳細な生成AI企業のカオスマップを解析したところ、わずか1分で企業名を正確に抽出することができました。
他のAIモデルと比較しても、GPT-4は解析できず、Claude 3は一部のみの解析にとどまっており、Gemini 1.5 Proの優位性は明らかです。
テキスト情報だけでなく画像を含めた、幅広い応用が期待されます。
動画解析
Google AI Gemini 1.5 Proがマジで凄かった❗️
— KEITO💻AIディレクター (@keitowebai) April 15, 2024
これは皆んな使ったほうが良いよ。
▼概要
・100万トークンという膨大な情報処理能力
・動画や音声ファイルを読み込んで内容を解析
・PDFなどのファイル読み込みにも対応
・APIでシステムに組み込むことが可能… pic.twitter.com/Fd3sDgknNn
この動画の内容を説明して
プロンプトと一緒に以下の動画を挿入
What will TED look like in 40 years? For #TED2024, we worked with artist @PaulTrillo and @OpenAI to create this exclusive video using Sora, their unreleased text-to-video model. Stay tuned for more groundbreaking AI — coming soon to https://t.co/YLcO5Ju923! pic.twitter.com/lTHhcUm4Fi
— TED Talks (@TEDTalks) April 19, 2024
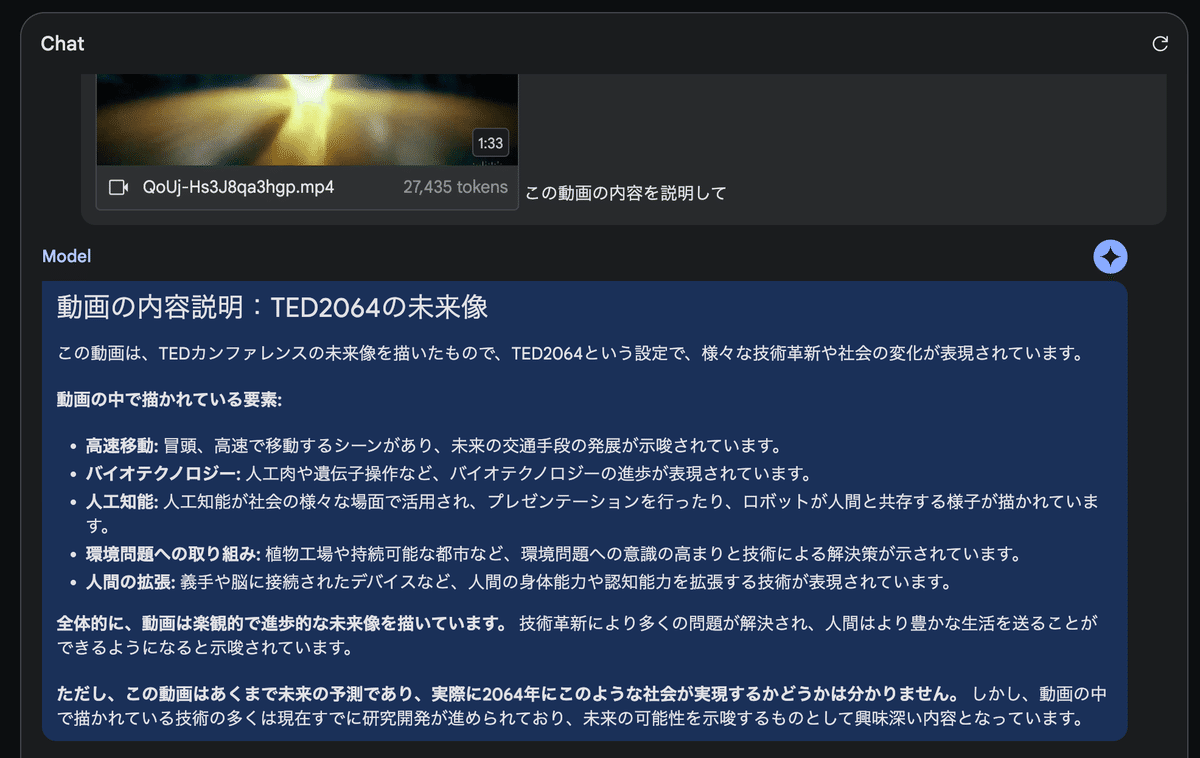
Gemini 1.5 Proは、OpenAIのSoraで生成された、未来のTEDを描いた1分半の動画を解析できました。
プロンプトで動画に関する説明文が与えられていない状況でも、動画の最後に短く映る "TED2064" のテキストを認識し、この動画がTEDの40年後の姿を予測したものであると理解しています。
Gemini 1.5 Proの動画解析機能は、シーン分析など、様々な分野での活用が期待されます。
音声認識
🎉 It’s a big day for @Google Gemini.
— Liam Bolling (@liambolling) April 9, 2024
Gemini 1.5 Pro now understands audio, uses unlimited files, acts on your commands, and lets devs build incredible things with JSON mode! It’s all 🆓. Here’s why it’s a big deal 👇
🔈 Gemini can hear
Gemini understands audio (up to 9.5… pic.twitter.com/HEdP4BMuza
音声を元に5問の選択問題を作成してください。問題の最後には、後で採点するための各問題の正解を記載するセクションを追加してください
プロンプトと一緒に以下の動画を mp3ファイルにしたものを挿入しました。