

Siriが目を持つ可能性|Appleがマルチモーダル言語モデル「FERRET」を公開

はじめに

2023年10月11日、Appleは画像とテキストを一体化したマルチモーダル大規模言語モデル(MLLM)、FERRETを発表しました。このモデルは、画像内の特定の領域について、テキストで言及する能力に焦点を当てて設計されています。画像とテキストのデータを効果的に組み合わせることで、新たな視覚的推論が可能になります。FERRETはGRITというデータセットで学習され、参照と画像内での対応付け(grounding)タスクで既存モデルを凌ぐ結果を出しています。
参照論文情報
タイトル: Ferret: Refer and Ground Anything Anywhere at Any Granularity
著者:Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, Yinfei Yang
URL:Ferret: Refer and Ground Anything Anywhere at Any Granularity (arxiv.org)
Github:https://github.com/apple/ml-ferret
ハイブリッド領域表現(Hybrid Region Representation)とは
論文では、FERRETが持つ独自の特徴は、画像内の「場所」と「物」についてのテキスト表現と、それらが画像のどの部分にマッチするかを一元的に解決する手法として、「ハイブリッド領域表現(Hybrid Region Representation)」が紹介されています。
Figure 2を参考にすると、従来の枠線のみを用いたアプローチだと、異なるオブジェクトでも同じような枠線を持つことがあるため、識別が曖昧になる可能性があります。しかし、ハイブリッド領域表現を使用することで、FERRETはこの曖昧さをクリアにし、銃やナイフのような異なるオブジェクトを正確に識別することができます。

一般に、これらの課題は個別に処理されますが、FERRETはそれらを統合し、場所の座標(点データ)と視覚的特性(形状や色など)を一緒に扱い、画像内の詳細を精緻に解釈します。このアプローチにより、FERRETは空間的な関連性を瞬時に把握できます。
アーキテクチャ
FERRETは、主に以下の三つの要素で構成されています。
画像エンコーダー: このモジュールは入力画像を処理し、関連する視覚的特徴を抽出します。
空間認識ビジュアルサンプラー(Spatial-Aware Visual Sampler): 空間情報と視覚特徴を組み合わせる新しいコンポーネントです。これにより、FERRETは領域について効果的に推論することができます。
大規模言語モデル(LLM): アーキテクチャの最終部分であり、画像とテキストの特徴を共同でモデリングします。
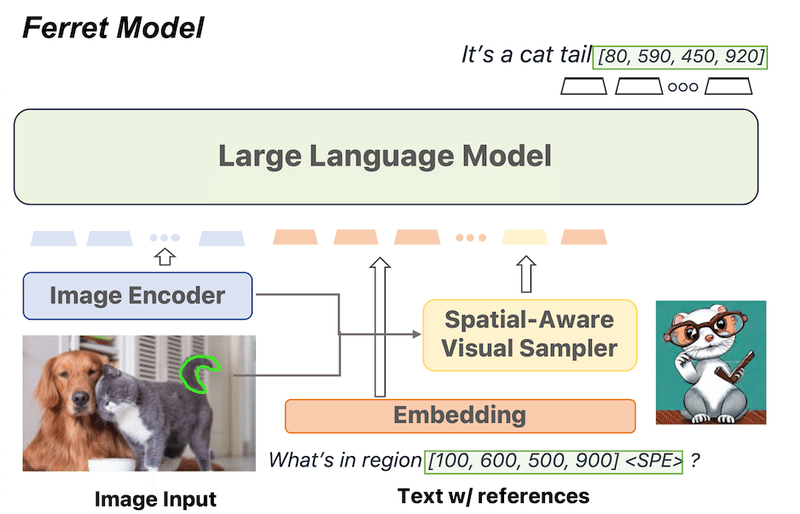
これらの要素は連携して働き、FERRETが言語的説明と視覚的内容の両方を理解することを可能にします。
データセット
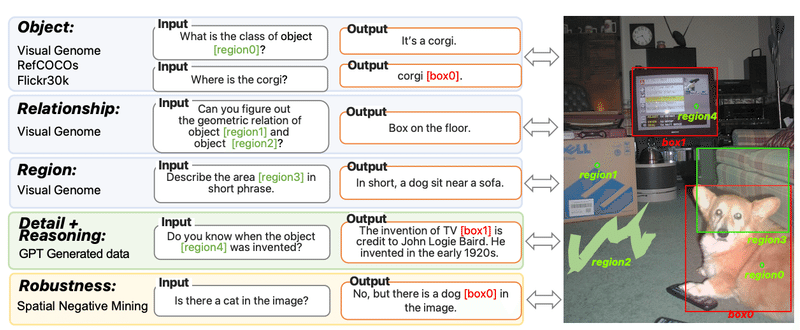
論文では、FERRETの学習データ「GRITデータセット」が紹介されています。このデータセットは110万ものサンプルで構成され、様々な地理的配置や物体の位置関係に関する詳細なデータを含んでいます。簡単に言うと、GRITはFERRETに「テキストと画像がどうリンクするか」を学習させます。その結果、FERRETは「テキストで何が言われているのか」「それが画像のどの部分に該当するのか」といった複雑な問題も、高い精度で解決できるようになります。
評価
FERRETモデルは、従来型の参照と基準設定(grounding)タスクにおいてはもちろん、マルチモーダルコミュニケーションでも他のMLLMを越えるパフォーマンスを発揮しています。その性能を厳密に評価するために「Ferret-Bench」と名付けた専用の評価フレームワークを導入されました。この評価体系には、新たに「参照の説明」、「参照の推論」、そして「会話中の地点特定」の3つのタスクが組み込まれています。

このフレームワークを用いて他のMLLMとの比較テストを実施した結果、FERRETは平均で20.4%も高いパフォーマンスを達成。特に、参照の理解や対話の文脈における認識など、マルチモーダルのタスクにおいて優れていることが確認できます。更には、オブジェクト認識の精度においても顕著な進歩を見せ、誤認率(ハルシネーション)を低減させたと報告されています。
まとめ
いかがだったでしょうか?iPhoneに搭載されている、「Siri」はLLMの進化と今回発表された「FERRET」により、さらに高度なマルチモーダルコミュニケーションが期待されます。今後の動向に注目です。これからも継続的に ChatGPT/AI 関連の情報について発信していきますので、フォロー (@ctgptlb)よろしくお願いします。この革命的なテクノロジーの最前線に立つ機会をお見逃しなく!