

ChatGPTの仕組み超解説:ChatGPTの裏側大解剖


はじめに
本記事では、ChatGPTを動かしている機械学習モデルをわかりやすく紹介していきます。大規模言語モデルの導入から始まり、GPT-3の学習を可能にした革新的な自己学習メカニズムに触れ、ChatGPTを特別なものにした新しい手法:人間のフィードバックによる強化学習について掘り下げていきます。
大規模言語モデル(LLM: Large Language Model)
ChatGPTは、大規模言語モデル(LLM: Large Language Model)と呼ばれる機械学習の自然言語処理モデルの一種を発展させたものです。LLMは、膨大な量のテキストデータを収集し、文章中のキーワードの関係を推論します。このモデルは、ここ数年の計算能力の向上とともに成長してきました。LLMは、インプットデータの量とその変数が増えれば増えるほど、その能力を発揮できます。
言語モデルの最も基本的な学習方法は、一連の単語の中からある単語を予測することです。最も一般的な学習方法は、次の単語を予測する方法 (next-token-prediction) と隠された単語を予測する方法 (masked-language-modeling) です。
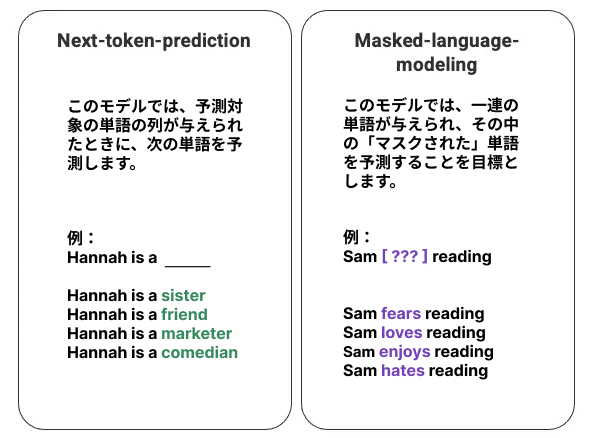
この基本的な処理手法は、LSTM(Long-Short-Term-Memory)モデルによって開発されることが多く、モデルは周囲の文脈から統計的に最も可能性の高い単語で空白を埋めていくことになります。この一連のモデルでは、2つの大きな限界があります。
一つは、周囲の単語を他の単語より重みづけすることができないことです。上記の例では、「読書」は「嫌い」と最もよく結びつきますが、データベースでは「サム」は熱心な読書家なので、モデルは「読書」よりも「サム」に比重を置き、「嫌い」ではなく「好き」を選択すべきかもしれません。
入力データは全体的に処理されるのではなく、個別に順次処理されます。つまり、LSTM が学習されるとき、文脈の幅は固定され、個別の入力を超えて数段階にわたってのみ拡張されることになります。このため、単語間の関係や導き出される意味の複雑さに限界があります。
この問題に対し、2017年、Google Brainのチームが transformers を導入しました。LSTMとは異なり、 transformersではすべての入力データを同時に処理することができます。自己注意メカニズムを用いて、このモデルは、言語配列の任意の位置に関連して、入力データの異なる部分にさまざまな比重を置くことができます。この機能により、LLMへの概念の埋め込みが大幅に改善され、非常に大規模なデータセットの処理が可能になりました。