

動画・画像・音声全てを読み込める最強マルチモーダルAI「Gemini 1.5 pro」解説

はじめに
Google DeepMindのCEOであるDemis Hassabis氏は、GoogleとAlphabetのCEOであるSundar Pichai氏とともに、次世代のAIモデル「Gemini 1.5」を発表しました。

Gemini 1.5は、先行モデルであるGemini 1.0から大幅に進化し、長文理解と複数モダリティにおける飛躍的な性能向上を実現しています👀
今回は、最新モデルであるGemini 1.5 Proの概要と使い方について詳細に解説していきます!
Gemini 1.5の主な特徴
1. 高効率なアーキテクチャ
Gemini 1.5は、TransformerとMixture-of-Experts (MoE)アーキテクチャの研究成果を取り入れています。
MoEモデルでは、入力に応じて最も関連性の高い「エキスパート」のニューラルネットワークのみを選択的に活性化させることで、モデルの効率性が大幅に向上しています。
ちなみに、今までのGPT-4などのモデルはTransformerモデルで、「どんな入力タスクでも、ネットワークを最大限使い切る構造」を採用しています。
2. 100万トークンの長文理解

Gemini 1.5 Proは、機械学習の革新により、最大100万トークンもの膨大な情報を一度に処理できるようになりました。
これは1時間の動画、11時間の音声、3万行以上のコード、70万語以上のテキストに相当します。研究では、さらに1000万トークンでの処理にも成功しているとのことです。
図のように、OpenAIの最新モデル「GPT-4 Turbo」の12万8000トークン・「Claude 2.1」が持つ20万トークンを大きく上回っているほど、超大なトークン量となっています。
この凄さを最も象徴しているのが、こちらのポスト。
Can Gemini 1.5 actually read all the Harry Potter books at once?
— Deedy (@deedydas) April 12, 2024
I tried it.
All the books have ~1M words (1.6M tokens). Gemini fits about 5.7 books out of 7. I used it to generate a graph of the characters and it CRUSHED it. pic.twitter.com/UCJiIh4SjY
ジェミニ 1.5 は実際にハリー・ポッターの本を一度にすべて読むことができますか? 私はそれを試してみました。
すべての本には約 100 万語 (160 万トークン) が含まれています。Gemini は 7 冊のうち約 5.7 冊に適合します。
私はこれを使用して文字のグラフを生成しましたが、見事に成功しました。
現在リリースされているハリーポッターの書籍全文章のうち8割程度を入力することが可能で、それから複雑な人物相関図を作成させています。
3. マルチモーダルでの高度な理解と推論
Gemini 1.5 Proは、動画を含む様々なモダリティにおいて、高度な理解と推論タスクを実行できます。
例えば、44分間のバスター・キートンの無声映画を与えると、プロットのポイントやイベントを正確に分析し、見落としやすい細部についても推論できるようになっています。

また、「動画」と「画像」を組み合わせた入力も可能です。
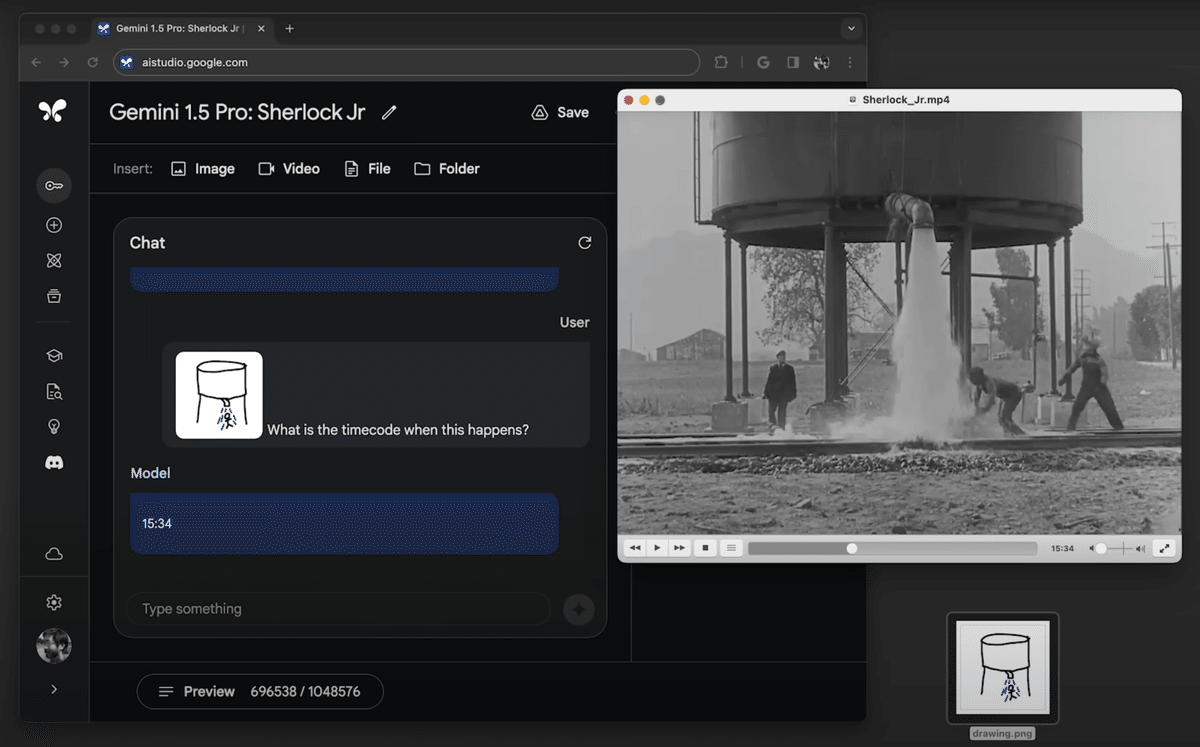
例えば、画像では入力した動画に対して、画像のような見た目の箇所がある部分を聞いて、実際にその秒数まで詳細に回答してくれています。
ただし、デモ動画では推論に対して数十秒の時間がかかっており、実践的にプロダクトに投入するにはあまりにもかかる時間が長いなど、問題点も浮き彫りになっています。
実際に使ってみる
アクセス
以下からグーグルAIスタジオにアクセスすることで、簡単に使用可能です!