

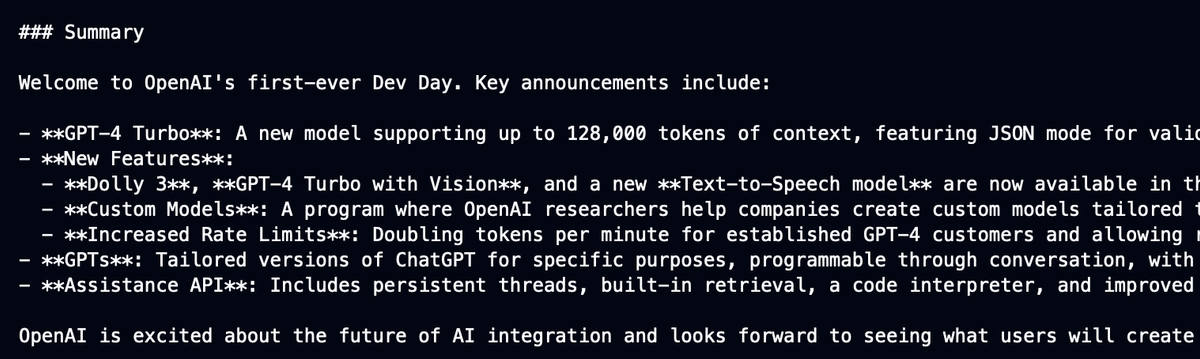
新モデル「GPT-4o」のAPIを使ってみる!

GPT-4o(oはomniの略:【omniは「全ての」を意味する】)は、テキスト、音声、動画の入力を処理し、テキスト、音声、画像形式で出力を生成するように設計されています。

背景
GPT-4o以前は、ユーザーは音声モードを使用してChatGPTと対話できましたが、これは3つの別々のモデルで動作していました。
GPT-4oは、これらの機能を統合し、テキスト、視覚、音声のすべての入力を同じニューラルネットワークで一貫して処理する単一のモデルに統合します。
この統一されたアプローチにより、テキスト、視覚、聴覚のいずれの入力も同じニューラルネットワークによって一貫して処理されるようになります。
現在のAPI機能
現在、APIはテキストと画像の入力のみをサポートし、出力はテキストのみで、gpt-4-turboと同じモダリティです。
音声などの追加モダリティは近日中に導入される予定です。
このガイドは、GPT-4oを使用してテキスト、画像、および動画の理解を開始するのに役立ちます。
はじめに
OpenAI SDK for Pythonのインストール
pip install --upgrade openai --quietOpenAIクライアントの設定とテストリクエストの送信
クライアントを使用するには、リクエストで使用するAPIキーを作成する必要があります。
すでにAPIキーを持っている場合は、この手順をスキップしてください。
APIキーを取得する手順:
新しいプロジェクトを作成する
プロジェクトでAPIキーを生成する
(推奨)APIキーを環境変数としてすべてのプロジェクトに設定する
設定が完了したら、最初のリクエストとしてモデルにテキスト入力を送信します。
最初のリクエストには、システムメッセージとユーザーメッセージの両方を使用します。
from openai import OpenAI
import os
# APIキーとモデル名を設定
MODEL="gpt-4o"
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "<環境変数として設定されていない場合のAPIキー>"))
completion = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "あなたは役に立つアシスタントです。私の数学の宿題を手伝ってください!"}, # システムメッセージ
{"role": "user", "content": "こんにちは!2+2を解いてくれますか?"} # ユーザーメッセージ
]
)
print("アシスタント: " + completion.choices[0].message.content)返答:

画像処理
GPT-4oは画像を直接処理し、画像に基づいてインテリジェントなアクションを実行できます。画像は2つの形式で提供できます:
Base64エンコード
URL
まず、使用する画像を表示し、この画像をBase64形式およびURLリンクとしてAPIに送信してみましょう。
from IPython.display import Image, display, Audio, Markdown
import base64
IMAGE_PATH = "data/triangle.png"
# 画像をプレビューしてコンテキストを提供
display(Image(IMAGE_PATH))
Base64画像処理
# 画像ファイルを開き、Base64文字列としてエンコード
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
base64_image = encode_image(IMAGE_PATH)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "あなたはMarkdownで応答する役に立つアシスタントです。私の数学の宿題を手伝ってください!"},
{"role": "user", "content": [
{"type": "text", "text": "この三角形の面積は?"},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}}
]}
],
temperature=0.0,
)
print(response.choices[0].message.content)出力:

URL画像処理
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "あなたはMarkdownで応答する役に立つアシスタントです。私の数学の宿題を手伝ってください!"},
{"role": "user", "content": [
{"type": "text", "text": "この三角形の面積は?"},
{"type": "image_url", "image_url": {"url": "https://upload.wikimedia.org/wikipedia/commons/e/e2/The_Algebra_of_Mohammed_Ben_Musa_-_page_82b.png"}}
]}
],
temperature=0.0,
)
print(response.choices[0].message.content)出力:

動画処理
APIに動画を直接送信することはできませんが、GPT-4oはフレームをサンプリングして画像として提供することで動画を理解できます。これにより、GPT-4 Turboよりも優れたタスクパフォーマンスを発揮します。
GPT-4o APIは2024年5月時点でまだ音声入力をサポートしていませんが、Whisperを使用して音声と視覚の両方を処理し、次の2つのユースケースを示します:
要約
質問と回答
動画処理のセットアップ
動画処理には、opencv-pythonとmoviepyの2つのPythonパッケージを使用します。
これらにはffmpegが必要なので、事前にインストールしておいてください。OSに応じて、brew install ffmpeg または sudo apt install ff
mpeg を実行する必要があります。
pip install opencv-python --quiet
pip install moviepy --quiet動画を2つのコンポーネント(フレームと音声)に分けて処理します。
import cv2
from moviepy.editor import VideoFileClip
import time
import base64
# 使用する動画はOpenAI DevDay Keynote Recapビデオです。動画はこちらで確認できます: https://www.youtube.com/watch?v=h02ti0Bl6zk
VIDEO_PATH = "data/keynote_recap.mp4"
def process_video(video_path, seconds_per_frame=2):
base64Frames = []
base_video_path, _ = os.path.splitext(video_path)
video = cv2.VideoCapture(video_path)
total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = video.get(cv2.CAP_PROP_FPS)
frames_to_skip = int(fps * seconds_per_frame)
curr_frame=0
# 指定されたサンプリングレートで動画からフレームを抽出
while curr_frame < total_frames - 1:
video.set(cv2.CAP_PROP_POS_FRAMES, curr_frame)
success, frame = video.read()
if not success:
break
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
curr_frame += frames_to_skip
video.release()
# 動画から音声を抽出
audio_path = f"{base_video_path}.mp3"
clip = VideoFileClip(video_path)
clip.audio.write_audiofile(audio_path, bitrate="32k")
clip.audio.close()
clip.close()
print(f"抽出されたフレーム数: {len(base64Frames)}")
print(f"音声が抽出されたパス: {audio_path}")
return base64Frames, audio_path
# 1秒ごとに1フレームを抽出します。`seconds_per_frame`パラメータを調整してサンプリングレートを変更できます。
base64Frames, audio_path = process_video(VIDEO_PATH, seconds_per_frame=1)
display_handle = display(None, display_id=True)
for img in base64Frames:
display_handle.update(Image(data=base64.b64decode(img.encode("utf-8")), width=600))
time.sleep(0.025)
Audio(audio_path)例1:要約
フレームと音声の両方が揃ったので、モデルに対して動画の要約を生成するためのいくつかの異なるテストを実行し、異なるモダリティを使用した場合の結果を比較します。視覚と音声の両方の入力からコンテキストを取得できるため、最も正確な要約が生成されるはずです。
視覚要約
視覚要約は、モデルに動画のフレームのみを送信して生成されます。フレームだけでは、モデルは視覚的な側面を捉えることができますが、スピーカーが説明している詳細は見逃します。
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "動画の要約を生成しています。動画の要約を提供してください。Markdownで応答してください。"},
{"role": "user", "content": [
"これらは動画のフレームです。",
*map(lambda x: {"type": "image_url", "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames)
],
}
],
temperature=0,
)
print(response.choices[0].message.content)OpenAI DemoDayの動画を入力:

予想通り、モデルは動画の視覚的な側面を高いレベルで捉えることができますが、スピーチで提供される詳細は見逃しています。
音声要約
音声要約は、モデルに音声のトランスクリプトを送信して生成されます。
音声のみの場合、モデルは音声コンテンツにバイアスがかかり、プレゼンテーションや視覚で提供されるコンテキストを見逃します。
GPT-4oへの{audio}入力は現時点では利用できませんが、Whisper-1モデルを使用して音声を処理します。
# 音声の書き起こし
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=open(audio_path, "rb"),
)
# オプション: トランスクリプトを表示
# print("Transcript: ", transcription.text + "\n\n")
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content":"""トランスクリプトの要約を生成しています。提供されたトランスクリプトの要約を作成してください。Markdownで応答してください。"""}
{"role": "user", "content": [
{"type": "text", "text": f"The audio transcription is: {transcription.text}"}
],
}
],
temperature=0,
)
print(response.choices[0].message.content)OpenAI DemoDayの音声を入力:
音声要約はスピーチで話された内容にバイアスがかかっていますが、視覚要約よりも構造が少ないです。
音声+視覚要約
音声と視覚を両方送信することで生成された要約は、視覚と音声の両方から情報を取得できるため、最も包括的な要約が得られます。
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content":"""動画とトランスクリプトの要約を生成しています。提供された動画とそのトランスクリプトの要約を作成してください。Markdownで応答してください。"""}
{"role": "user", "content": [
"これらは動画のフレームです。",
*map(lambda x: {"type": "image_url", "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
{"type": "text", "text": f"The audio transcription is: {transcription.text}"}
],
}
],
temperature=0,
)
print(response.choices[0].message.content)OpenAI DemoDayの音声と動画のフレームを入力:

視覚と音声の両方を組み合わせることで、動画の詳細かつ包括的な要約が得られます。
例2:質問と回答
動画を処理し、前と同様に質問を行い、入力モダリティを組み合わせた場合の利点を示すために3つのテストを実行します:
視覚Q&A
音声Q&A
視覚+音声Q&A
質問:
「サム・アルトマンが窓を上げたりラジオをオンにする例を出した理由は?」
視覚Q&A
qa_visual_response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "動画を使用して提供された質問に回答してください。Markdownで応答してください。"},
{"role": "user", "content": [
"これらは動画のフレームです。",
*map(lambda x: {"type": "image_url", "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
QUESTION
],
}
],
temperature=0,
)
print("Visual Q&A:\n" + qa_visual_response.choices[0].message.content)出力:

音声Q&A
qa_audio_response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content":"""トランスクリプトを使用して提供された質問に回答してください。Markdownで応答してください。"""}
{"role": "user", "content": f"The audio transcription is: {transcription.text}. \n\n {QUESTION}"},
],
temperature=0,
)
print("Audio Q&A:\n" + qa_audio_response.choices[0].message.content)出力

音声+視覚Q&A
qa_both_response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content":"""動画とトランスクリプトを使用して提供された質問に回答してください。"""}
{"role": "user", "content": [
"これらは動画のフレームです。",
*map(lambda x: {"type": "image_url", "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
{"type": "text", "text": f"The audio transcription is: {transcription.text}"},
QUESTION
],
}
],
temperature=0,
)
print("Both Q&A:\n" + qa_both_response.choices[0].message.content)出力:

3つの回答を比較すると、最も正確な回答は動画の視覚と音声の両方を使用して生成されます。
サム・アルトマンは基調講演中に窓を上げたりラジオをオンにすることについて言及していませんが、背後で示される例は、モデルが複数の機能を1つのリクエストで実行する改善された能力を示しています。
結論
音声、視覚、テキストなどの多くの入力モダリティを統合することで、モデルの多様なタスクでのパフォーマンスが大幅に向上します。
このマルチモーダルアプローチにより、情報の理解と対話がより包括的になり、人間が情報を認識し処理する方法により近づきます。
現在、GPT-4o APIはテキストと画像の入力をサポートしており、音声機能は近日中に追加予定です。
値段
値段は、GPT-4 Turbo の半額です。
