

【徹底解説】Difyナレッジ機能の全て

今回は、先日のバージョン0.6.11のアップデートで追加されたウェブサイトとの連携機能を含めたDifyのナレッジ機能についてご紹介します。
※ナレッジ機能はブラウザ版とローカル版で機能や制限に違いがあるのでご注意ください。
ナレッジ機能とは?
Difyのナレッジベース機能はRAGシステム開発の各段階をユーザーが開発する際に、個人またはチームのナレッジベースを簡単に作成・管理しやすくするための機能です。
この機能を活用すれば、多種多様なテキストデータ(txt、Markdown、docx、html、jsonl、pdfファイル)や構造化データ(csv、excelなど)を簡単に取り込むことができます。
さらに、以下のようなデータベースからデータを同期することが可能です。
ウェブページ
Notion
例えば、会社が既存の知識ベースと製品ドキュメントを用いてAIカスタマーサポートアシスタントを構築したい場合、Difyにドキュメントをデータセットとしてアップロードし、少し設定をするだけで対話型アプリケーションを構築することができます。
このようにして大変だった構築作業を早く簡単に完了させることが可能になります。
バージョン0.6.11のアップデートでFireCrawlと連携し、指定したウェブサイトのURLからスクレイピングでサイトの内容を取得しデータを保存・RAG化することが可能になりました。
従来はツールやプログラムを用いてテキストデータを保存しDifyにテキストデータをアップロードする必要があったのに対して、Dify上でURLと少量のパラメータを入力するだけでRAGシステムが作成できるようになり、とても便利になりました。
ウェブサイトのデータをナレッジ化する
FirecrawlのAPIキーを登録する
まず最初にナレッジのタブを開いて知識を作成で新しいナレッジを作成してください。
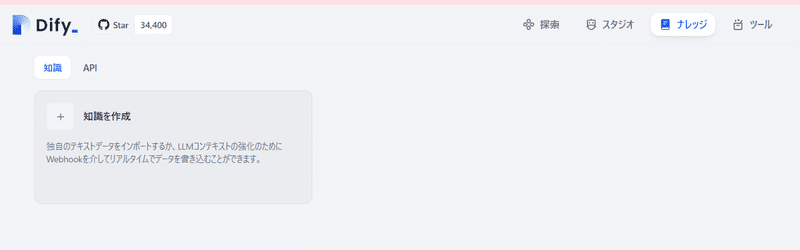
ウェブサイトから同期を選択し、Configureをクリックしてください。

WebsiteのConfigureを選択してください。

Get your API key from firecrawl.devをクリックしてFireCrawlのウェブサイトを開き、アカウント登録をしてください。

APIキーを取得するために、Accountをクリックしてください。
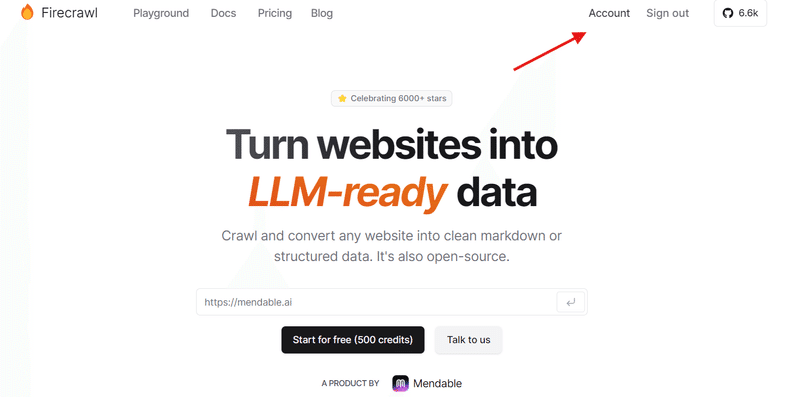
API Keyの欄からAPIキーをコピーしてください。
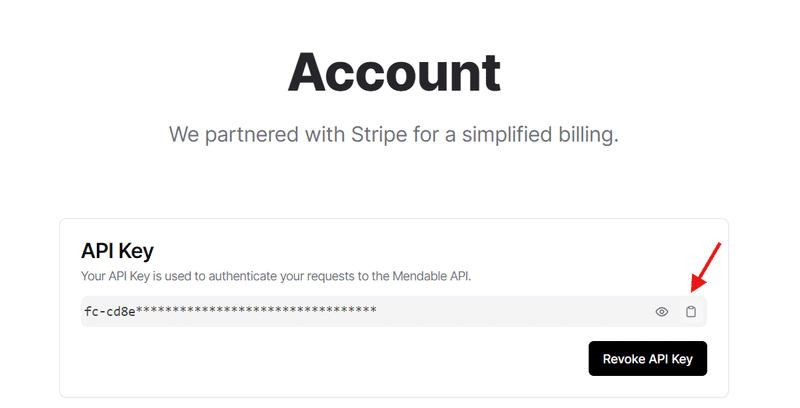
API Keyの欄にコピーしたキーを貼り付け、保存を押して保存してください。(画像はキーの一部のみの例です)

ACTIVEとなっていたら成功です。

Dify公式ドキュメントを読み込む
データソースの選択画面に戻り、URLの入力欄にhttps://docs.dify.aiと入力してください。
また、Limit(読み込むページ数の上限)とMax depth(取得する深さ)を任意の値に設定した後にRunを押してください。
Nonetypeのエラーが発生する場合はLimitを減らす、Max depthを増やすなどこの値を変更して調整してください。

スクレイピング処理には時間がかかる場合があるので少し待ちます。
(FireCrawlフリープランの場合は5ページ/分となっています)

Select Allで全てのページを選択して次へをクリックしてください。
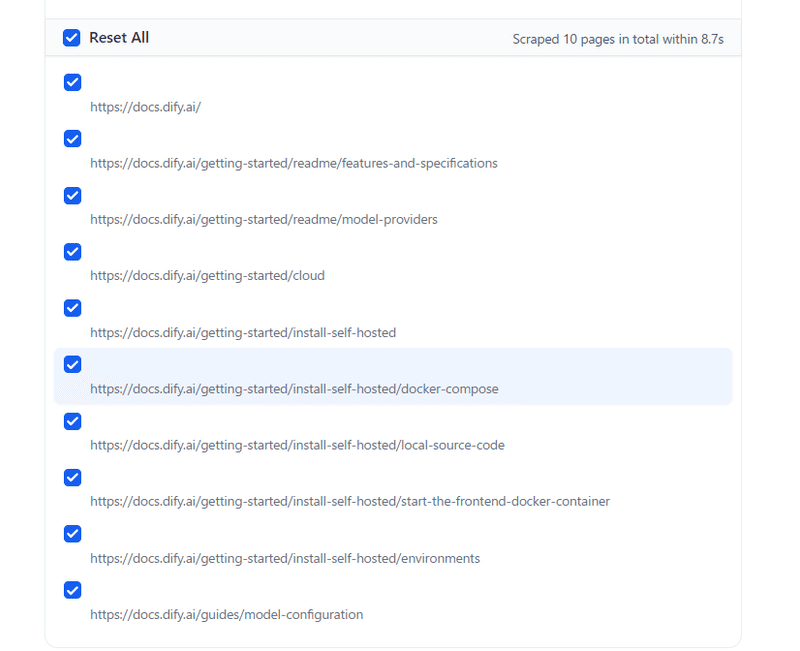
テキストの前処理とクリーニングのページでは自動、高品質、ハイブリッド検索を選択してください。
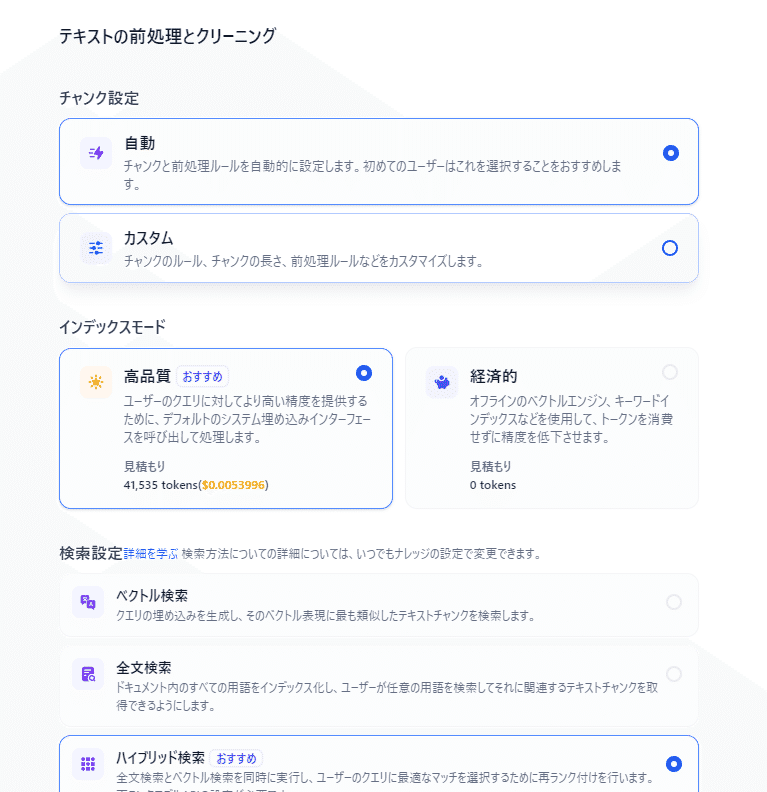
再ランクモデルが選択できない場合は、モデルの設定からcohereのセットアップを選択して下さい。

Get your API key from cohereをクリックし、cohereアカウントを作成してください。

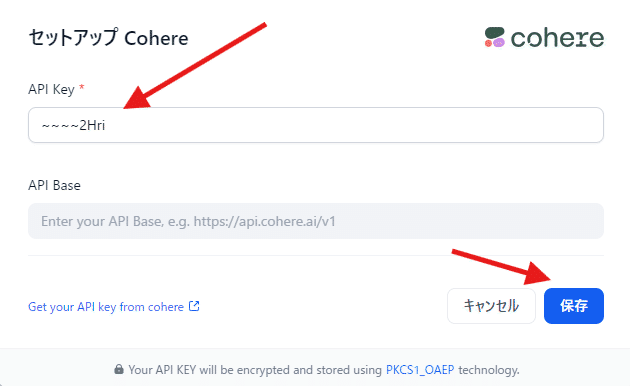
API KeysのページからCreate trial keysをクリックして作成されたキーをコピーしてください。

API Keyを貼り付け、保存をクリックしてください。
再ランクモデルを選択し、保存して処理をクリックして保存します。
※日本語の場合はmultilingualモデルがおすすめです。

全て100%になれば処理は完了です。

直接テキストファイルをアップロードしてナレッジ化する
テキストファイルをアップロードする
データソースの選択ページのテキストファイルからインポートのタブを選択してください。

アップロードするテキストは任意のテキストファイルをご利用ください。
デモではDify公式サイトのドキュメントをスクレイピングしたデータを利用します。
※ブラウザ版のフリープランの場合は一度にアップロード可能な個数が20個までの制限があります。