

DifyでRAGを構築する方法を徹底解説!note記事検索ボットを作成

はじめに
外部データを扱う際に、RAG (Retrieval Augmented Generation) を活用して、効率的に情報を検索・抽出できれば非常に便利です。
RAGは強力な技術ですが、これまで専門的な知識や技術がないと構築するのは難しい技術でした。
Difyでは、RAGを比較的簡単に構築できる様々な機能を提供しています。
本記事では、Difyのナレッジ機能、知識取得ノード、そして並列処理能力を活用し、ChatGPT研究所が公開している300以上のnote記事を検索するチャットボットを作成する方法を解説します。
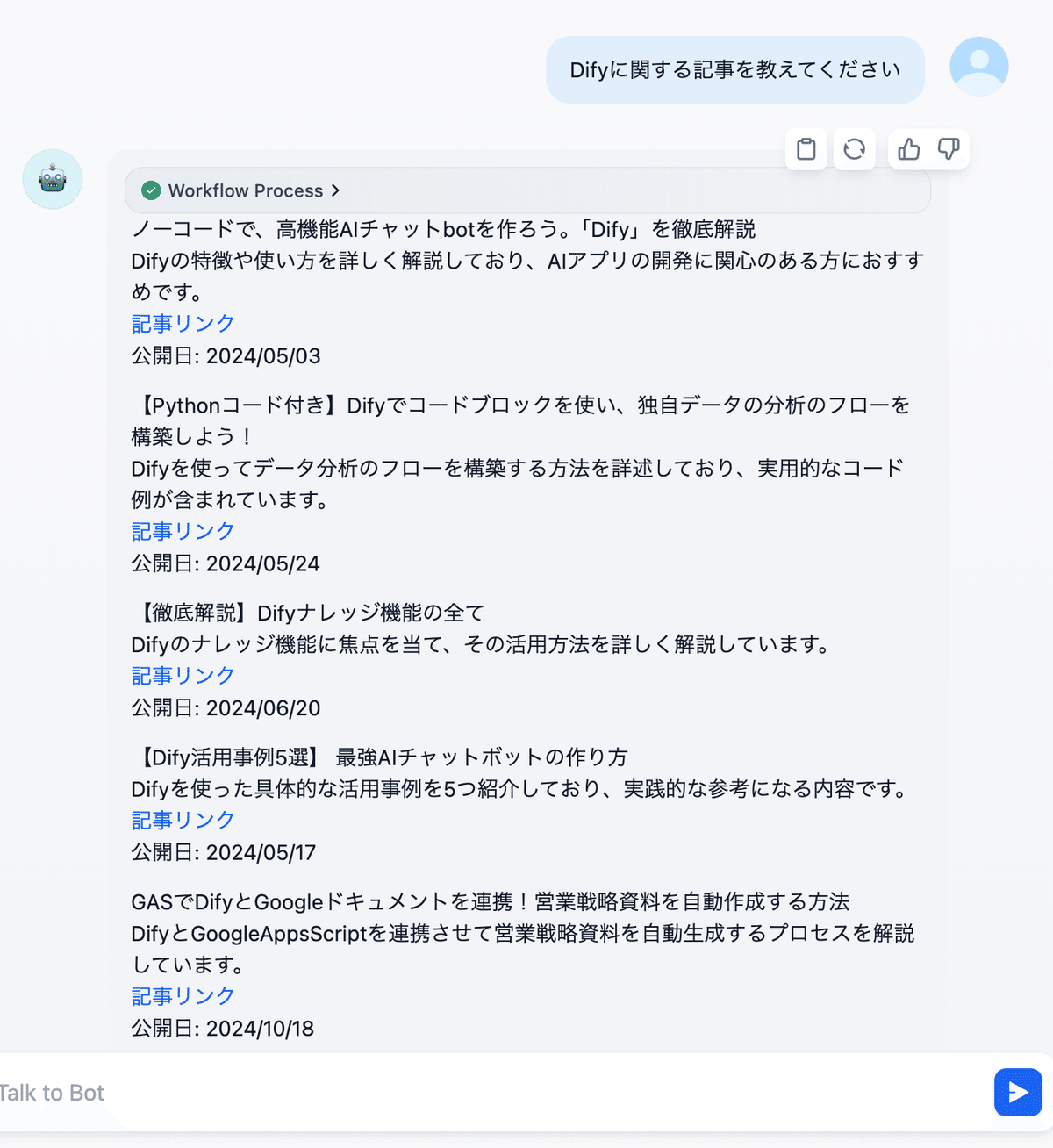
具体的には、以下の内容を解説します。
note記事データの準備と整形 (GASとChatGPTを活用)←RAGではデータの整備が非常に重要
Difyでのナレッジ機能の活用 (インデックス方法、埋め込みモデル、検索設定、Rerankモデルなど)
Cohere APIキーについて(embeddingモデル、rerankモデルの比較情報)
チャットフローの構築 (並列処理による最適化)
記事では、DifyでRAGを構築する際の以下の工夫を、ChatGPT研究所のnote記事検索チャットボットの作成の様子を題材に、具体的に説明します。
長い情報を1つのチャンクに収めるデータ整形テクニック
これにより、文脈を適切に捉え、より精度の高い検索結果を得ることができます。複数のナレッジベースを並列処理して検索を最適化する工夫
Difyの並列処理能力を活用することで、大量のデータでも効果的に検索できます。
もちろん、これらのテクニックは他のRAG構築ケースにも応用可能です。Difyを使ってRAGを構築したいと考えている方は、ぜひ最後までお付き合いください。
今回の記事で解説する内容は、中級者以上向けの部分もあり、Difyに関する知識に自信がない方は、本記事を読み進める前に、下記の記事を参照することをおすすめします。
RAGとは?
RAG (Retrieval Augmented Generation) とは、外部の知識ベースから関連情報を取得し、その情報を基に、LLM (大規模言語モデル) が回答を生成する手法です。
従来のLLMは、学習データに含まれる情報のみをもとに回答を生成しているので、学習データにない最新の情報や、専門性の高い情報を含む回答を生成することは困難でした。
そこで、RAGを使うことで、最新の情報を反映した回答や、特定の分野に特化した専門的な回答を生成することが可能になります。
例えば、企業の社内文書や顧客データなどを知識ベースとして利用すれば、社内問い合わせ対応やカスタマーサポートに特化したチャットボットを構築できます。
RAGの仕組み
例えば、ユーザーが「最新のAI技術トレンドについて教えて」と質問した場合、RAGは以下のような手順で回答を生成します。
ユーザーの質問を理解し、関連するキーワードを抽出
外部の知識ベース (例えば、AI関連の論文データベース) から、キーワードに合致する情報を検索
検索結果をLLMに提供
LLMは、提供された情報と自身の知識を組み合わせ、最新のAI技術トレンドに関する回答を生成
このように、RAGは、LLMの能力を拡張し、より幅広い情報に基づいた回答を生成することを可能にする技術です。
下記に英語ですが、RAGに関する分かりやすい図解を紹介します。

note記事データの準備
Difyで効果的なRAGを構築するには、データを適切な形式に整形することが重要です。
今回は、記事タイトル、本文、公開日などの情報を1つのチャンクに収めるようにデータを整形します。
チャンク
文章を意味的なまとまりごとに分割したものです。例えば、長い小説を章ごとに分けるようなイメージです。
※Difyのナレッジ機能では、チャンク分けが改行や段落単位で行われます。
RAGでは、ユーザーの質問に対して、関連性の高いチャンクを探し出し、その内容を元に回答を生成します。
理由としては、記事情報が別々のチャンクに分割されてしまうと、同じ記事の情報として認識されず、RAGで記事タイトル、概要、公開日をセットで検索結果として出力できないからです。
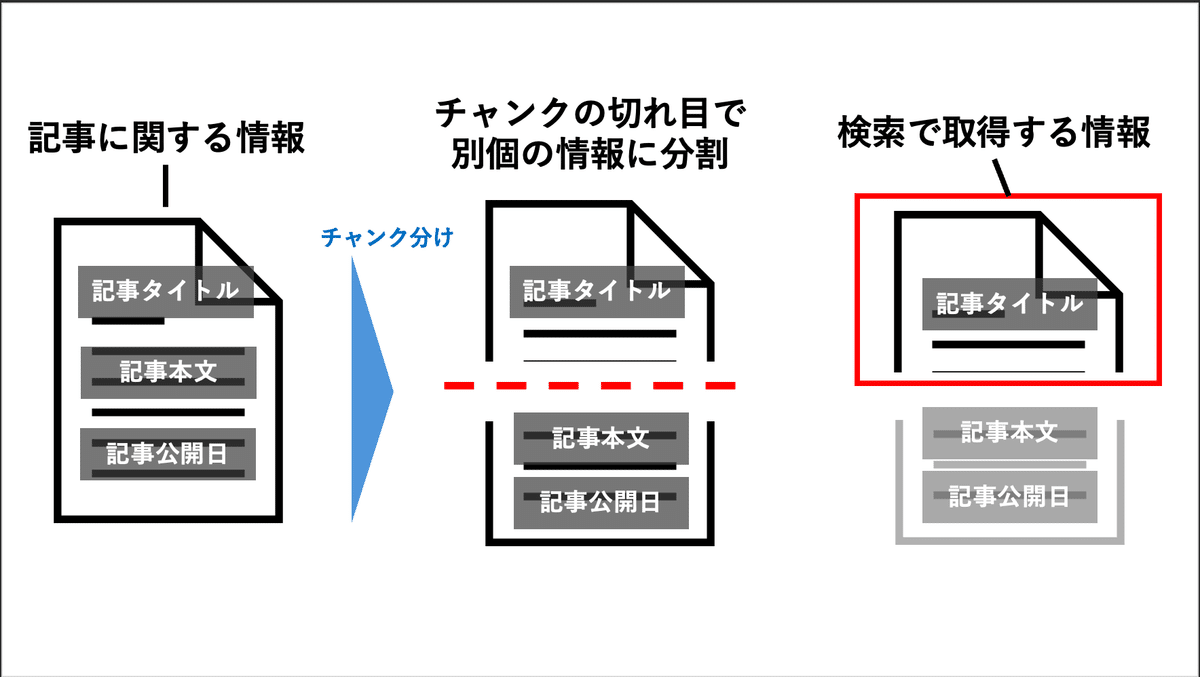
Difyのナレッジ機能では、チャンク分けが改行や段落単位で行われ、チャンク長は最大4000未満です。

Microsoftによると、チャンクのトークン数が大きくなるほど精度が下がるという結果が出ており、今回は1000文字程度に情報が収まるようにデータを整形していきます。
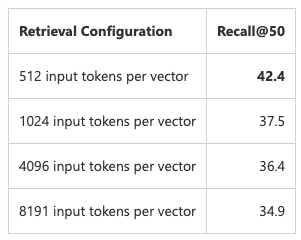
Azure AI Search: Outperforming vector search with hybrid retrieval and ranking capabilities
データ形式例:
"note記事ID":"note記事の一意のID","Title":"記事のタイトル","記事概要":"記事本文の要約,""公開日":"記事が公開された年月日"具体的な手順は以下に記載しますが、下記は今回のケースに関することなので、内容は参考程度にご確認いただいて、ご自身が保持しているデータに合わせて整形を行ってください。
1.note記事データのエクスポート
ChatGPT研究所のnoteアカウントから、過去の記事データをエクスポートします。エクスポート形式はXMLです。
2.データの整形
エクスポートしたXMLデータを、Difyが理解できる形に整形します。整形にはChatGPT(o1-mini推奨)とGoogle Apps Script (GAS) を使用します。
xml形式のデータを整形して、最終的に下記のようなデータ形式に整えていきます。
"note記事ID":"note記事の一意のID","Title":"記事のタイトル","記事概要":"記事本文の要約,""公開日":"記事が公開された年月日"具体的な手順は以下のとおりです。
手順に従って、やりたいことをChatGPTに伝えてGASコードを作成してもらいながら進めることができます。
Google Apps Script (GAS) の準備
Googleスプレッドシートを作成し、「拡張機能」>「Apps Script」を選択してスクリプトエディタを開きます。
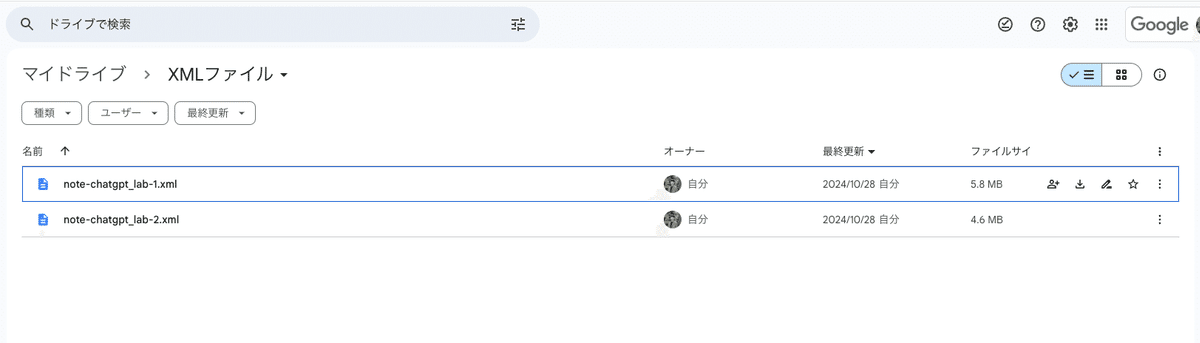
XMLファイルのGoogleドライブIDを取得
エクスポートしたXMLファイルをGoogleドライブにアップロードし、ファイルIDを取得します。(Googleドライブでファイルを右クリック、「共有」→「リンクをコピー」で取得したURLからファイルIDを取得)
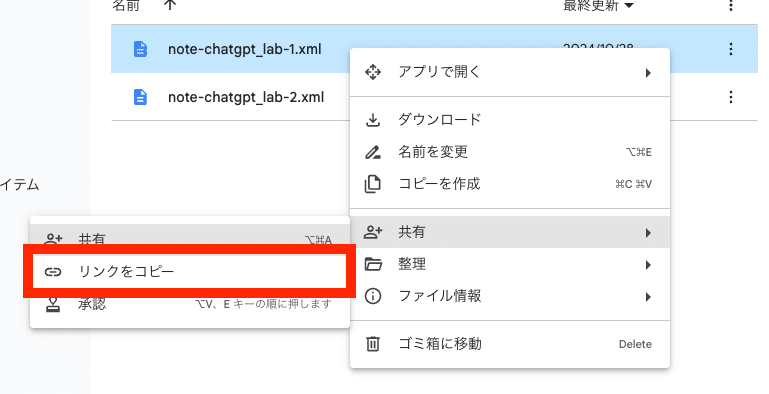
例:https://drive.google.com/file/d/【ファイルID】/view?usp=sharing
GASコードの作成と実行
スクリプトエディタに、以下の処理を行うGASコードを作成・実行します。
1.XMLファイルの読み込み
先ほど取得したxmlのファイルIDをGASのプロパティに保存するなどして、ファイルIDを用いてGoogleドライブからXMLファイルを読み込みます。
2.データの抽出
XMLファイルから、各記事の「タイトル」「リンク」「本文」「公開日」を抽出します。
3.本文の要約
OpenAIのAPIキーを用いて、GPT-4o-miniモデルに取得した各記事の本文を渡し、500〜700文字程度の要約を生成します。
ポイント:OpenAI APIキーは、スクリプトのプロパティとして安全に保存・管理します。
4.データ形式の作成
各記事の情報を "note記事ID":"記事ID","Title":"記事のタイトル","記事概要":"記事の要約","公開日":"公開日" の形式で1行にまとめます。

5.Wordにコピペ
スプレッドシートに、整形されたデータが出力されていることを確認して、出力されたデータは、Wordにコピーして保存します。
1行に整形したデータの行を全部選択して、Wordに移動して、「形式を選択してペースト」で「テキスト」を選択して貼り付けます。

しっかりと個別のデータが改行で区切られていることも確認します。

今回、いくつかのファイル形式でナレッジを作成して試してみましたが、一番チャンク分けが正確に反映されたWordファイルを使用しています。
Difyでのナレッジベース作成
前章で準備した整形済みnote記事データを用いて、Difyでチャットボットが回答を生成する際に参照するナレッジベースを作成します。
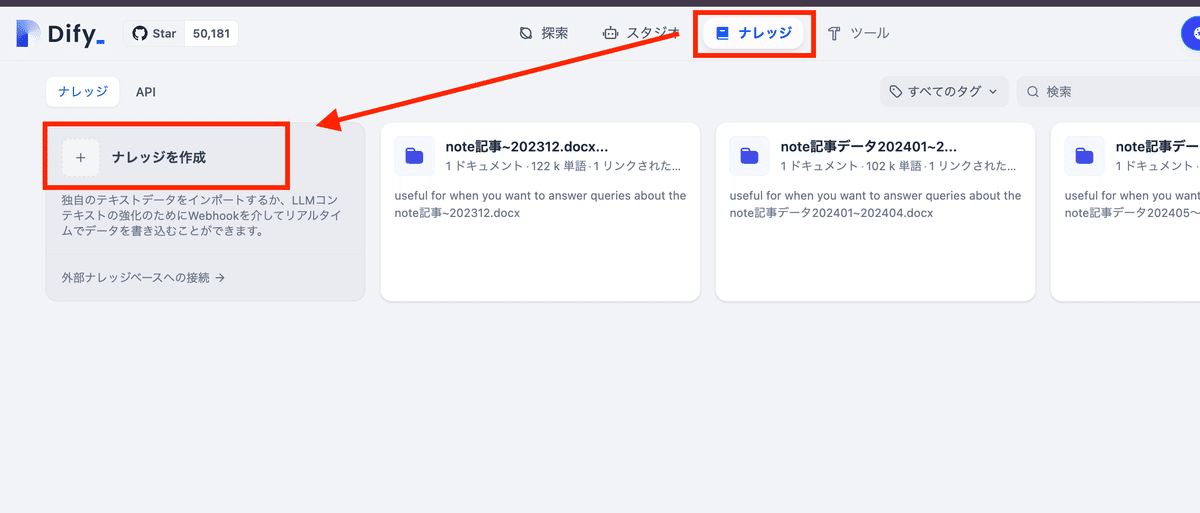
1.ナレッジベースの作成
Difyにログインし、「ナレッジ」から「ナレッジを作成」ボタンをクリックします。
2.データのアップロード
整形したnote記事データをアップロードします。
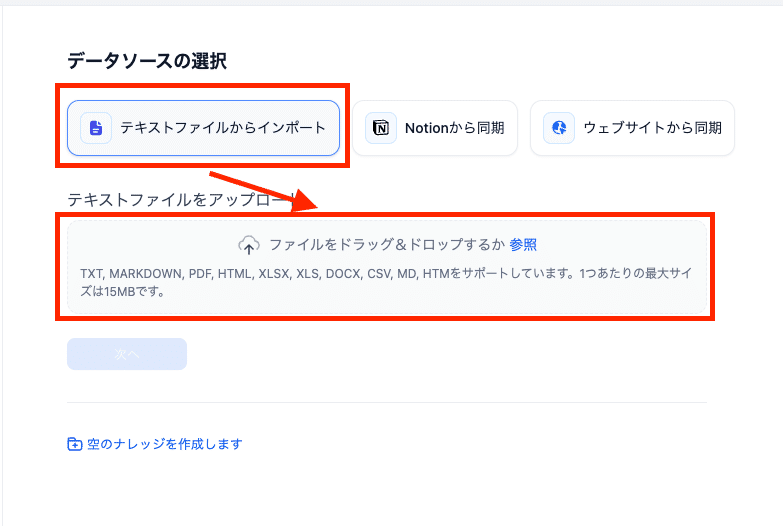
3.ナレッジベースの設定
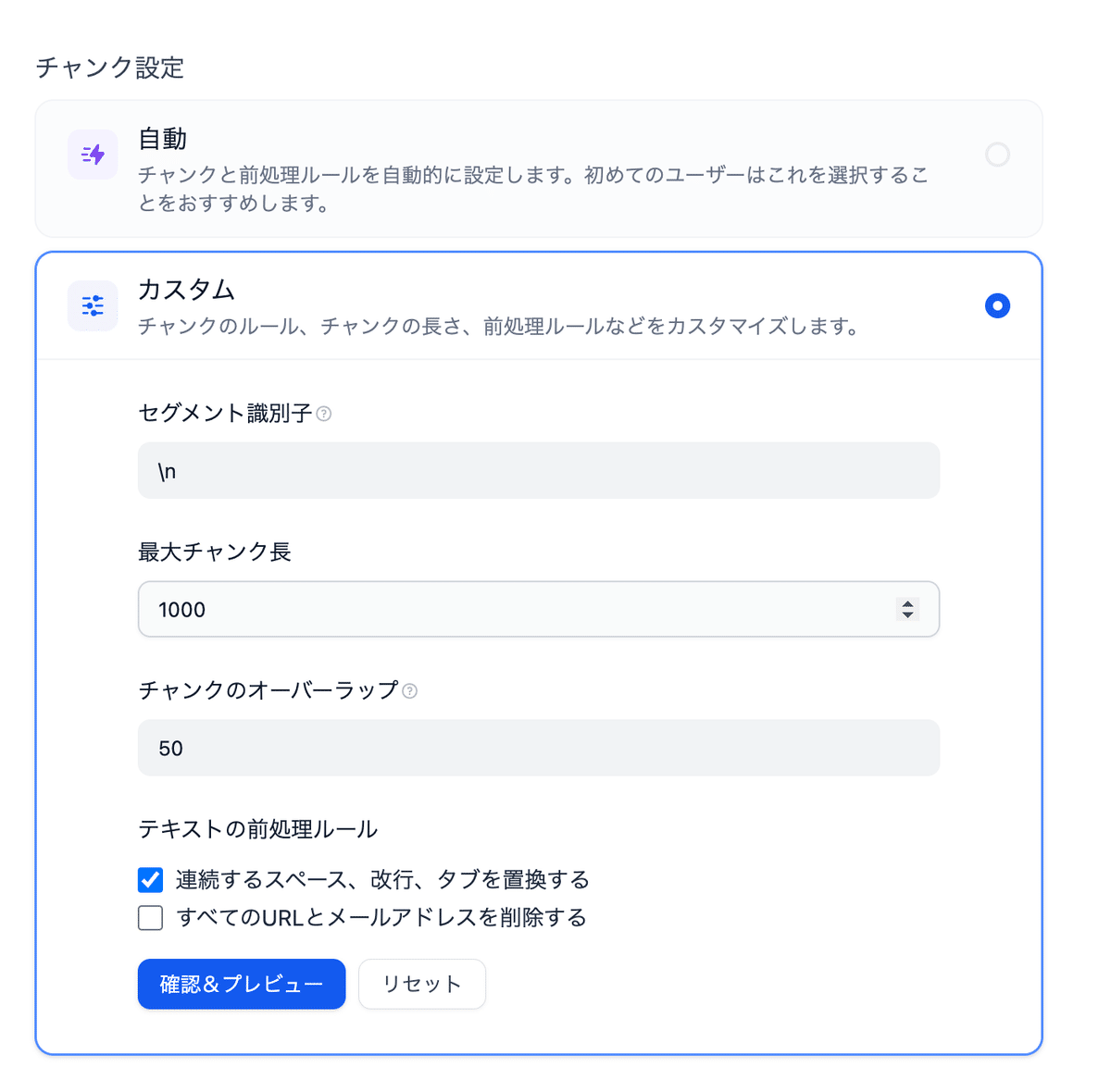
チャンク設定では、カスタムを選択して、下記のように設定します。
インデックス方法は検索の精度と速度に応じて、「高品質」または「経済的」を選択します。
高品質: ベクトル検索を用いるため、精度の高い検索が可能ですが、処理速度が遅くなります。
経済的: キーワード検索を用いるため、処理速度は速いですが、精度が低くなります。
今回は高品質を選択します。

テキストデータをベクトルに変換する際に使用する埋め込みモデルを選択します。Cohereの下記のモデルを使用します。

埋め込みモデル、rerankモデルにcohereのモデルを設定するためにはAPI連携が必要です。
cohereを連携してない方は下記の記事を参考に必ず設定を行ってください。
検索設定では「ハイブリッド検索」を選択すると、ベクトル検索とキーワード検索を組み合わせ、より精度の高い検索を実現できます。
下記のようにrerankモデル(rerank-multilingual-v3.0)を設定します。
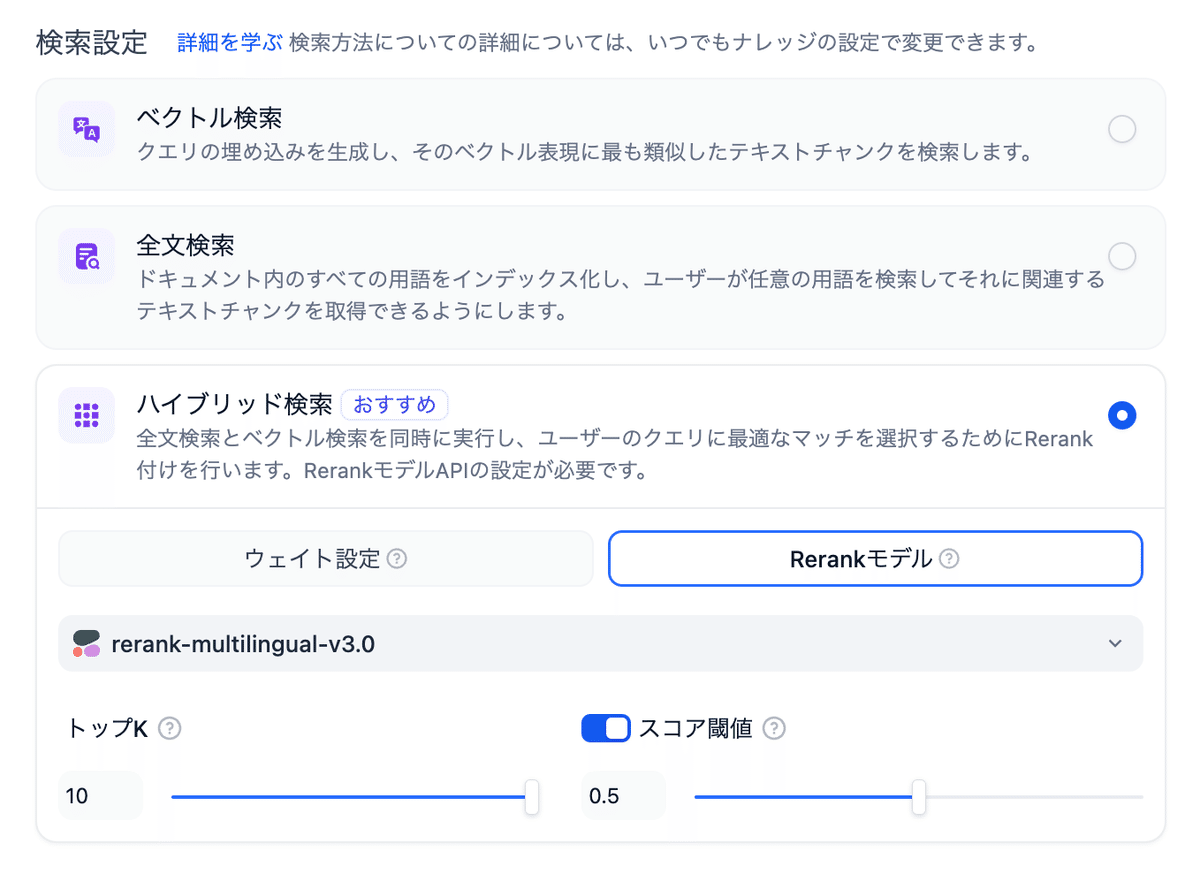
TopK: 検索結果として表示する最大記事数です。ここでは最大の10で設定します。
スコア閾値: 検索結果に含めるための最小スコアを設定します。今回は0.5で設定します。
4.ナレッジベースの保存
設定が完了したら「保存」ボタンをクリックします。
補足:embeddingモデル、rerankモデルについて
本記事では、Cohereの埋め込みモデルとRerankモデルを使用していますが、DifyはOpenAIのモデルやjinaのモデルなどにも対応しています。必要に応じて、モデルを変更することも可能です。
今回、cohereを用いた背景としては、openAIのembeddingモデルや、Jinaのモデルを試したところ、日本語においてはcohereが一番精度が高かったことがあります。


※いずれも「chatgptに関する記事を教えてください」と検索テストを実施。
embeddingモデル、rerankモデルともにcohereを用いた場合に、10記事を取得してくれました。
その他、おすすめのembeddingモデルやrerankモデルをご存知の方はコメントなどで教えていただけますと幸いです。
また、英語においては、jinaのembeddingモデルが優秀という結果があります。

Cohere APIキーについて
本記事では、ナレッジベース作成時とチャットフロー構築時に、Cohereの埋め込みモデルとRerankモデルを使用します。これらのモデルを利用するには、CohereのAPIキーが必要となります。
Cohereは、APIキーを以下の2種類提供しています。
Trial API Key: 無料で利用できますが、使用量に制限があります。
Production API Key: 有料ですが、Trial API Keyよりも多くのリクエストを送信できます。
Cohereの埋め込みモデルとRerankモデルは、大量のテキストデータを処理するため、Trial API Keyではすぐにリクエスト制限に達してしまう可能性があります。そのため、本記事では、Production API Keyを使用することを前提として解説を進めます。
有料のAPIキーはダッシュボードの「Production keys」から取得してください。

Cohere APIキーの料金プランについては、Cohereのウェブサイト を参照してください。
